SGENet: 2019-Conference on Computer Vision and Pattern Recognition ¶
本模型由南京理工大学PCALab和清华大学共同发表:《Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks》。
论⽂链接:https://arxiv.org/pdf/1905.09646
一、提出背景¶
卷积神经⽹络(CNN)通过收集不同层次和不同部分的语义⼦特征来⽣成复杂对象的特征表⽰。这
些⼦特征通常可以以分组形式分布在每⼀层的特征向量中,代表各种语义实体。然⽽,这些⼦特征的激活往往在空间上受到相似模式和噪声背景的影响,从⽽导致错误的定位和识别。本⽂提出了⼀个空间组增强(SGE)模块,该模块可以通过为每个语义组中的每个空间位置⽣成⼀个注意因⼦来调整每个⼦特征的重要性,从⽽每个单独的组可以⾃主地增强其学习的表达,并抑制可能的噪声。注意因素仅由各组内部的全局和局部特征描述符之间的相似性来引导,因此SGE模块的设计⾮常轻量级,⼏乎没有额外的参数和计算。
二、SGENet 模型设计¶
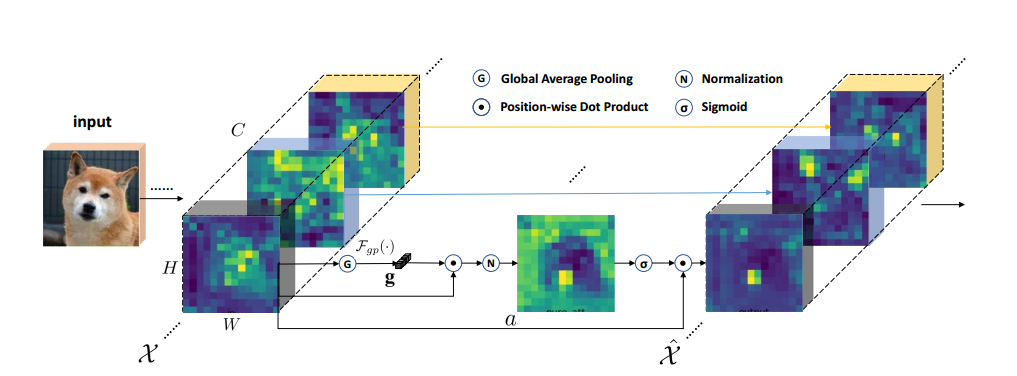
三、模型创新¶
1、加在EEGNet的最前⾯
原始EEG数据先经过SGE处理。此时EEG的输⼊shape不应该是(288,1,22,1000),因为经过第⼆⾏代码时,需要对第⼆维度的通道分组求特征重要性,⽽我们的这个维度是扩出来的1,所以分不了,也就⽆法完成SGE的功能。所以输⼊的EEG.shape = (288,22,5,200)/(288,22,20,50)。
这就出现⼀个新的问题:每个通道的1000的数据点怎么分?
1000的公因⼦有:1, 2, 4, 5, 8, 10, 20, 25, 40, 50, 100, 125, 200, 250, 500, 1000,根据实验,是H和W⼤⼩越相近越好,也就是特征图越像正⽅形越好。
2、加在EEGNet的最后⾯
原始EEG数据不先经过SGE处理,此时EEG的输⼊可以是最佳的(288,1,22,1000)。在经过EEGNet的处理后,其第⼆维度的1在经过每层卷积时发⽣了变化,超过了1。
# Step 1
xn = x * self.avg_pool(x) # bs*g, dim//g, h, w
# Step 2
xn = xn.sum(dim=1, keepdim=True) # bs*g, 1, h, w
然后,这个被划分为group的特征图通过: $$ \mathbf{XN} = \frac{\mathbf{X}}{HW} \sum \mathbf{X} $$
X除以HW并累加的⽅法,⽣成了加权后的特征图,其中H*W为特征图的像素点个数,由avg_pool操作保证输出特征图形状⼀致。接着执⾏了XN的加权操作。
t=xn.view(b*self.groups,-1) #bs*g,h*w
t=t-t.mean(dim=1,keepdim=True) #bs*g,h*w
std=t.std(dim=1,keepdim=True)+1e-5
t=t/std #bs*g,h*w
t=t.view(b,self.groups,h,w) #bs,g,h*w
t=t*self.weight+self.bias #bs,g,h*w
t=t.view(b*self.groups,1,h,w) #bs*g,1,h*w
将加权后的张量t进⾏标准化操作,即每个元素减去均值并除以⽅差。在这个阶段,t被视为group
的全局平均值(rolling-mean)和标准差(rolling-std)。group内的每个值被减去它们的group的
rolling-mean,再除以该group的rolling-std。标准化的结果被保存在张量t中。并且,执⾏了激活函
数的计算,即t * self.weight + self.bias,其中self.weight和self.bias是可学习的参数。
x=x*self.sig(t)
#然后,执⾏了x * sigmoid of t 操作,并将结果再次分组
if __name__ == '__main__':
input=torch.randn(288,1,22,1000)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)
#将正常化之后的结果乘以原始输⼊“x”,并将结果reshape成最终输出的形式。
#最后,⽤input中的随机张量来测试该模型,并打印出其最终的输出形状。