GhostNet: CVPR-2020 ¶
华为诺亚⽅⾈实验室提出的⼀个端侧模型,更加轻量⾼效,性能⾼于MobileNet,ShuffleNet。
GHostNet仅通过少量计算(cheap operations)就能⽣成⼤量特征图的结构。
一、提出背景¶
卷积神经网络推动了计算机视觉诸多任务的进步,⽐如图像识别、⽬标检测等。
但在嵌入式设备上部署深度学习模型的一个困难就是模型过大,以及所需要的计算量过大。
⽐如我们所熟悉的ResNet-50,它有大概25.6M的参数量,按照32位存储,就需要102.4MB的内存空间,
同时处理一张 224×224的图⽚的计算量大概是4.1B。
因此,深度神经网络设计的最新趋势是探索便携式(Portable)和高效(Efficient)的网络架构,为移动设备提供更适合的应用方式。
一些研究提出了模型的压缩方法,⽐如剪枝、量化、知识蒸馏等;还有一些则着重于高效的网络结构设计。 本工作从减少冗余特征图的角度出发,提出了一种全新的神经网络基本单元Ghost模块, 从而搭建出轻量级神经网络架构GhostNet。
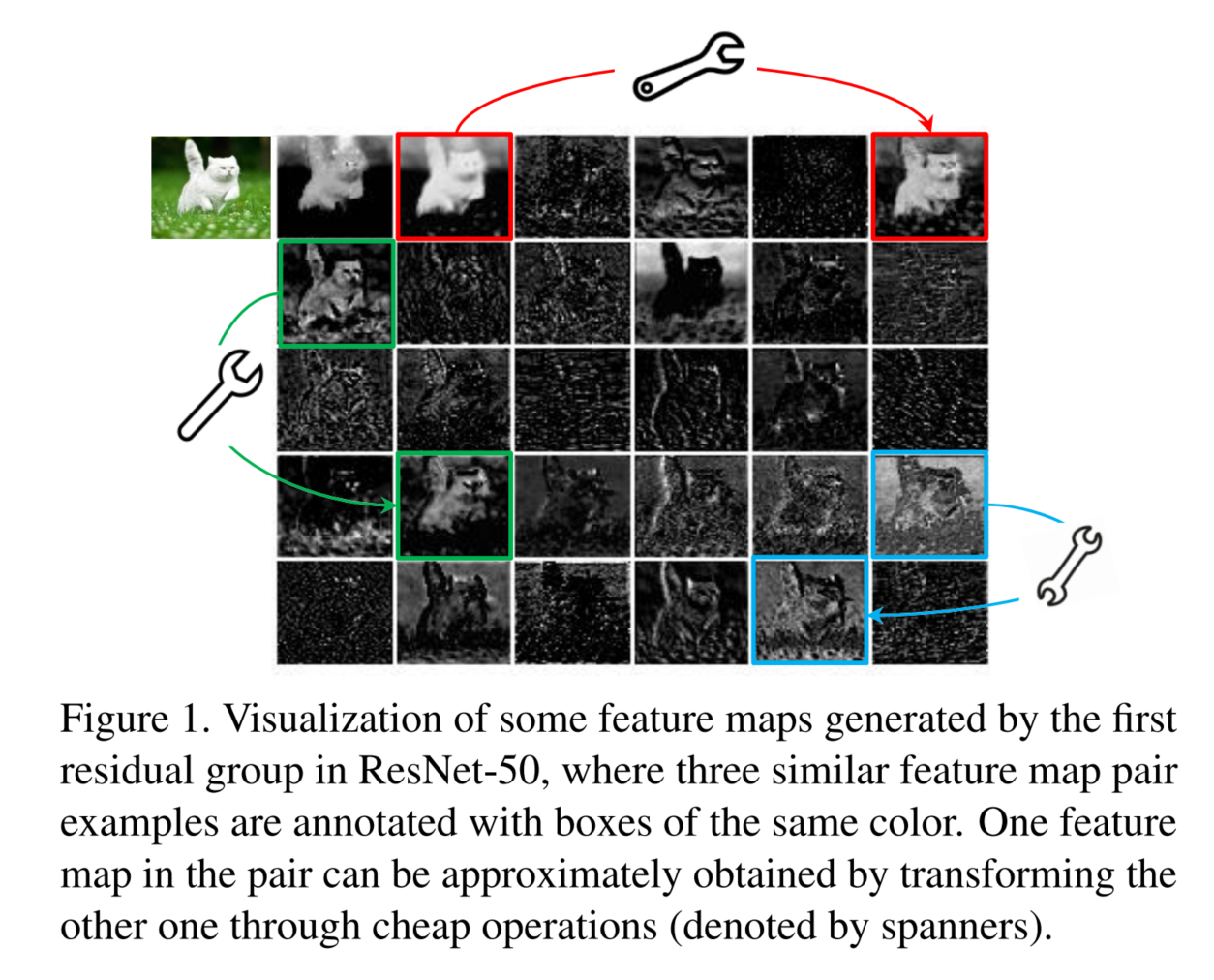
如图所⽰,是由ResNet-50中的第⼀个残差块⽣成的某些中间特征图的可视化。从图中我们可以
看出,这⾥⾯有很多特征图是具有⾼度相似性的(在图中分别⽤不同的颜⾊⽰意),换句话说,就是
存在许多的冗余特征图。所以从另⼀个⻆度想,我们是不是可以利⽤⼀系列的线性变化,以很⼩的代
价⽣成许多能从原始特征发掘所需信息的“幽灵-Ghost”特征图呢?(冗余的特征图是⾮常有必要
的,可以保证⽹络对输⼊数据的理解更为全⾯),这个便是整篇⽂章的核⼼思想。
本⽂提出的Ghost模块是⼀种新颖的即插即⽤模块,主要⽬的是使⽤更少的参数来⽣成更多特征
图。具体来说,深度神经⽹络中的每⼀个卷积层将会分为两部分:
第⼀部分:常规的卷积,但是特征图的数量将会严格控制,因为不能让计算量太⼤。
第⼆部分:也是⽣成⼀些特征图,只是不采取常规的卷积来⽣成,⽽是通过简单的 "线性变换"。
第⼀部分:常规的卷积,但是特征图的数量将会严格控制,因为不能让计算量太⼤。
第⼆部分:也是⽣成⼀些特征图,只是不采取常规的卷积来⽣成,⽽是通过简单的 "线性变换"。
二、Ghost-Module结构¶
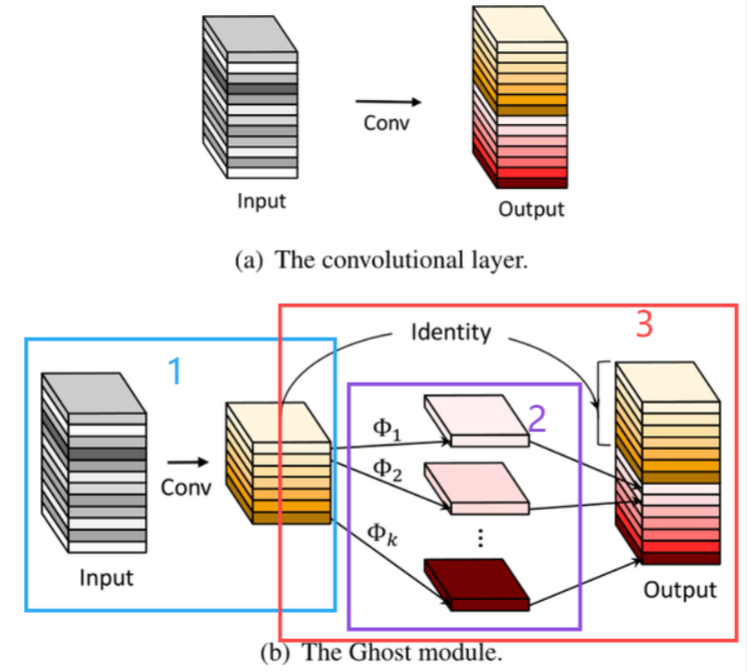
Ghost-Module可分成蓝⾊1、紫⾊2、红⾊3:
蓝⾊部分1:是⼀个普通的Conv2D操作,作者并没有把其的通道设置的很⼤,我们假设输出通道数为 m ( m < n ), 其中n 为Output输出的通道数。
紫⾊部分2:⼀个分组卷积操作,通过分组卷积可以得到Output输出特征图下⾯渐红的,我们想要得 到的有利于分类的“幻影-Chost”特征图。
红⾊部分3:蓝⾊部分的Conv2D卷积得到的通道数为m的特征+紫⾊分组卷积得到的通道数( m − 1 ) s的通道数相加。
蓝⾊部分1:是⼀个普通的Conv2D操作,作者并没有把其的通道设置的很⼤,我们假设输出通道数为 m ( m < n ), 其中n 为Output输出的通道数。
紫⾊部分2:⼀个分组卷积操作,通过分组卷积可以得到Output输出特征图下⾯渐红的,我们想要得 到的有利于分类的“幻影-Chost”特征图。
红⾊部分3:蓝⾊部分的Conv2D卷积得到的通道数为m的特征+紫⾊分组卷积得到的通道数( m − 1 ) s的通道数相加。
其中:Φ为线性变换。实际操作中Φ的变换方法不固定,可以是 3x3 卷积核或者 5x5 卷积核。另外,理论上可以使用不同尺寸大小的卷积核组合进行线性变换操作,但考虑到 CPU 或 GPU 的推理情况,作者建议全部使用 3x3 卷积核或全部使用 5x5 卷积核。
⼀些概念和问题:
1、"廉价的线性运算 (cheap linear operation)" 是指:分组卷积,其中 分组数 = 数据输⼊通道数。
2、Ghost与已有的⽅法相⽐区别在哪⾥:
以往的⽅法,⽐如深度可分离卷积是先使⽤Depthwise Convolution处理空间信息,再使⽤
Pointwise Convolution处理不同channel之间的信息。相⽐之下,Ghost 模块先使⽤常规的卷积得到
⼀些特征,再使⽤廉价线性变换(分组卷积)得到另⼀些特征(“幽灵/幻影”)。⽽且,这个 cheap
linear operation 可以有其他很多种变化。⽐如说 仿射变换(affine transformation) 和⼩波变换
(wavelet transformation)。
补充:
Affine transformation 是⼀种在⼆维或三维空间中对图形进⾏变换的数学⽅法,它包括了平移、旋
转、缩放和剪切等操作。这种变换保持了图形的“仿射性质”,意味着它不会改变图形中点的共线性
(即,如果三个点在变换前共线,变换后仍然共线)和平⾏性(即,如果两条线在变换前平⾏,变换后仍然平⾏)。
基本类型
- 平移(Translation):将图形沿着某个⽅向移动⼀定的距离。
- 旋转(Rotation):围绕⼀个固定点(旋转中⼼)按⼀定⻆度旋转图形。
- 缩放(Scaling):改变图形的⼤⼩,可以是均匀缩放(各⽅向⽐例相同)或⾮均匀缩放(各⽅向⽐例不同)。
- 剪切(Shear):使图形沿着某⼀⽅向倾斜,造成⼀种拉伸效果。
矩阵表⽰
在⼆维空间中,⼀个仿射变换可以⽤⼀个3x3的矩阵表⽰,形式如下:
\[
\begin{bmatrix} a & b & t_x \\ c & d & t_y \\ 0 & 0 & 1 \end{bmatrix}
\]
其中,a,b,c,d定义了旋转和缩放,tx,tytx,ty 定义了平移。如果 a,b,c,d构成的2x2矩阵
是正交的,那么这个变换还包括了旋转。在三维空间中,仿射变换可以⽤⼀个4x4的矩阵表⽰,形式如下:
\[
\begin{bmatrix}
a_{11} & a_{12} & a_{13} & t_x \\
a_{21} & a_{22} & a_{23} & t_y \\
a_{31} & a_{32} & a_{33} & t_z \\
0 & 0 & 0 & 1
\end{bmatrix}
\]
仿射变换在计算机图形学、计算机视觉、图像处理、机器学习等领域有着⼴泛的应⽤。例如,在图像
处理中,仿射变换可以⽤来校正图像的⼏何失真;在机器学习中,它可以⽤来对数据进⾏预处理,以
提⾼算法的性能。仿射变换是线性变换的⼀种,它通过添加平移向量扩展了线性变换,使其能够处理
更复杂的空间变换问题。
三、构建GhostNet¶
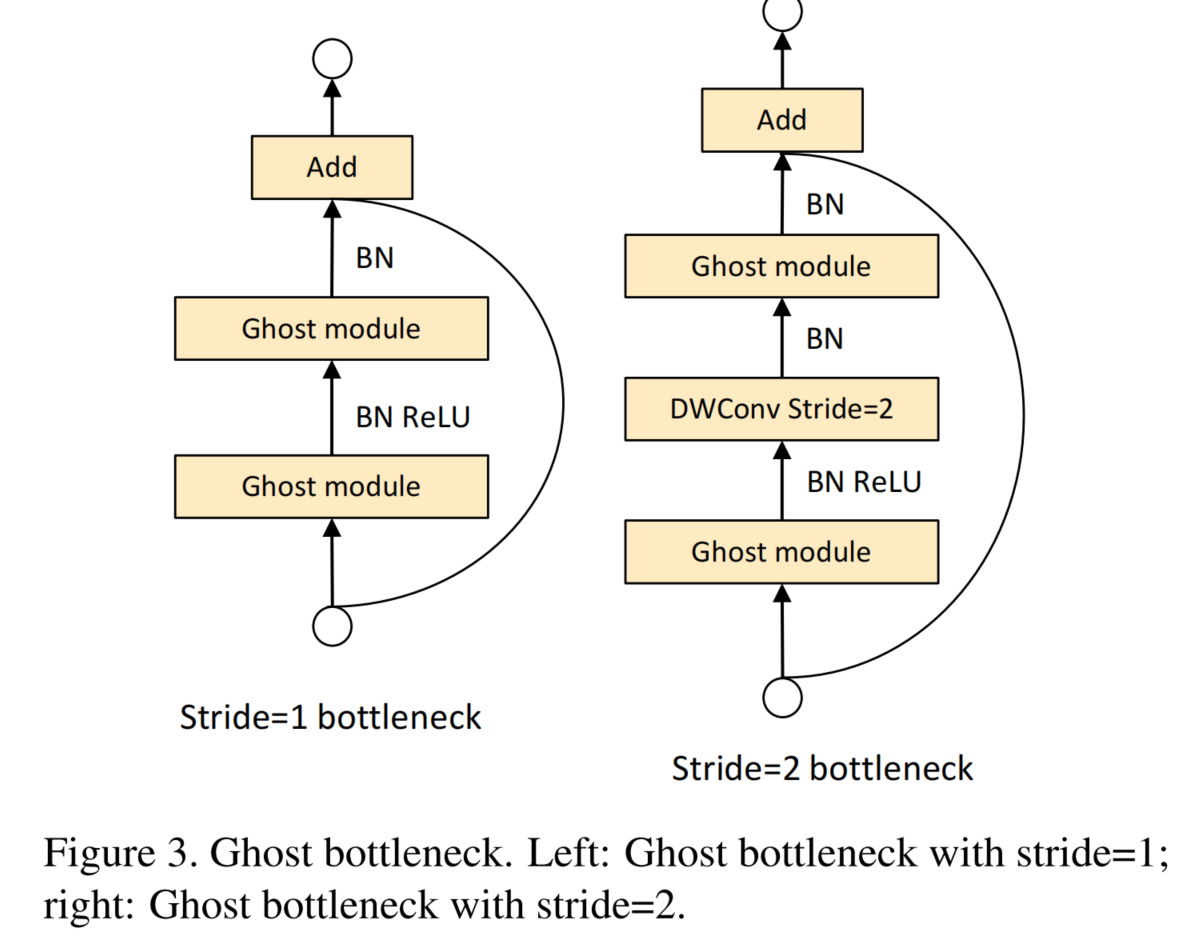
Ghost Bottleneck:作者设计了2种Ghost bottleneck(G-bneck)。分别对应着 s=1 和 s=2 的情况。
Ghost bottleneck由两个堆叠的Ghost模块组成:
第1个Ghost模块:扩展层,增加了通道数。这⾥将输出通道数与输⼊通道数之⽐称为扩展⽐例(expansion ratio)。
第2个Ghost模块:减少Channel,以与shortcut路径匹配。然后,使⽤shortcut连接这两个Ghost模
块的输⼊和输出。第⼆个Ghost模块之后不添加ReLU,其他层在每层之后都应⽤了批量归⼀化(BN)
和ReLU⾮线性激活。
注意:考虑到效率的因素,实作中Ghost模块中的第1阶段的初始卷积是点卷积(Pointwise Convolution)。
代码实现:
https://github.com/huawei-noah/Efficient-AI-Backbones
四、GhostNet改进EEG SOTA的方案¶
GhostNet改进EEG SOTA的⽅案:
GhostNet可完美替代深度可分离卷积,对于包含深度可分离的SOTA:EEGNet、EEG-TCNet模型可以
使⽤GhostNet替代深度可分离卷积。