EfficientViT: CVPR-2023
Evan2you
本模型由港中⽂和微软研究院于2023年共同提出,EfficientViT 是⼀类专注于提⾼推理速度和
内存效率的视觉Transformer模型。与传统的视觉Transformer模型相⽐,EfficientViT 通过减少计算冗余、优化内存访问和重新分配参数等⽅法,显著提升了模型的推理性能和内存利⽤率。本⽂的⽬的是深⼊解析EfficientViT模型
的结构设计和优化策略,并探讨其在实际应⽤中的性能优势。
一、提出背景
视觉Transformer的发展
⾃从Vision Transformer (ViT) 模型被提出以来,Transformer在计算机视觉领域得到了⼴泛应⽤。
Transformer模型通过⾃注意⼒机制(Self-Attention)能够捕捉全局依赖关系,在⼤规模数据集上的
表现优异。然⽽,传统的Vision Transformer模型存在以下⼏个问题:
• 计算开销⼤:Transformers的⾃注意⼒机制需要对输⼊的每个位置进⾏全局计算,导致计算量与输⼊的⻓度平⽅成正⽐。
• 内存访问效率低:Transformer中的⼀些操作(如张量变形、逐元素计算)往往是内存受限的,导致模型在GPU/CPU上的推理速度受限。
轻量化视觉Transformer的研究
为了提⾼视觉Transformer的推理效率,近年来提出了许多轻量化的Transformer变体,如
MobileViT、DeiT等。这些模型虽然在参数量和FLOPs(浮点运算次数)上做了优化,但很多未能显著
提升推理速度。因此,EfficientViT的研究⽬标是通过系统性地分析影响Transformer推理速度的主要因素,设计出能在推理速度和准确率之间取得更好平衡的模型架构。
二、EfficientViT 模型设计
内存效率
计算效率
参数效率
通过对这些⽅⾯的改进,EfficientViT不仅显著减少了模型的计算时间,并在多个任务上取得了优异的性能表现。
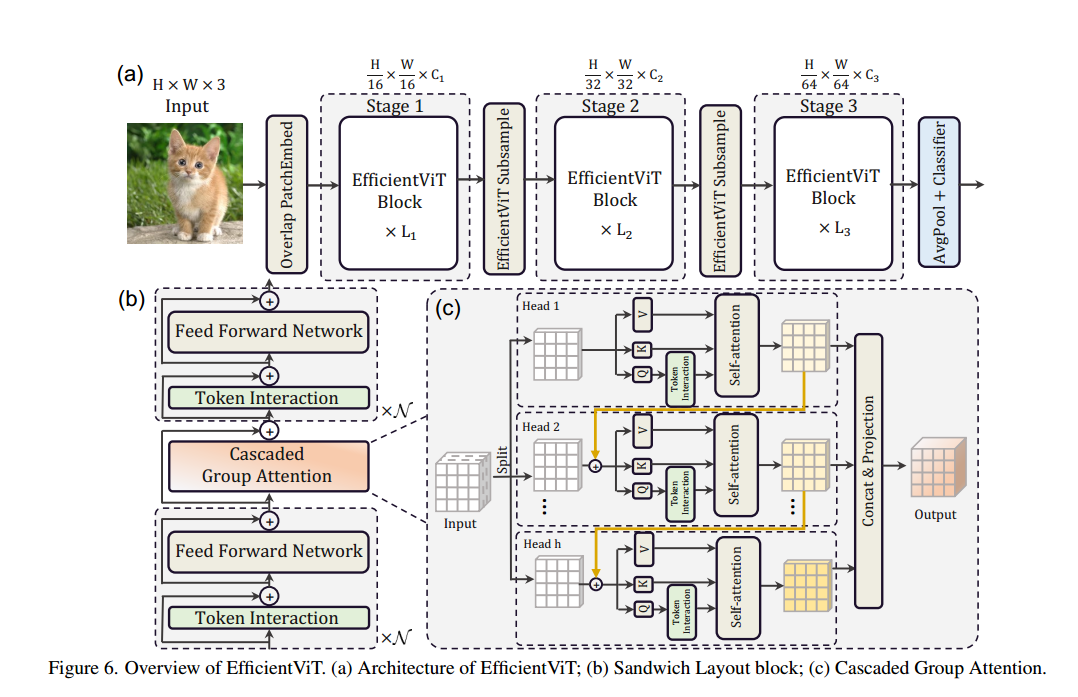 EfficientVit 结构图
EfficientVit 结构图
内存效率优化
内存受限操作的分析
在Transformer模型中,内存受限操作主要包括张量的频繁变形、逐元素操作(如逐元素加法)以及归
⼀化操作(如LayerNorm)。这些操作需要频繁访问内存,⽽内存访问延迟往往会成为推理速度的瓶颈。
提出Sandwich结构
为了解决上述问题,EfficientViT提出了⼀种Sandwich布局的结构设计。传统的Transformer模型通常
在每个块中使⽤等量的多头⾃注意⼒(MHSA)和前馈神经⽹络(FFN)层,⽽EfficientViT则引⼊了
⼀个“夹⼼式”的布局结构,即在每个块中只使⽤⼀个⾃注意⼒层,并在其前后插⼊多个FFN层。这种设计的优点在于:
• 减少内存受限操作:MHSA操作是内存受限的主要来源,⽽FFN层的计算更多是基于通道的,内存效率更⾼。
• 增强通道间通信:通过增加FFN层的数量,可以在不同通道之间进⾏更⾼效的信息交互。
公式化描述为:
\[
X_{i+1} = F_i \left( A_i \left( F_i \left( X_i \right) \right) \right)
\]
其中,Ai是⾃注意⼒层,Fi是FFN层,Xi是第i层的输⼊特征。通过这种结构设计,EfficientViT有效减少了MHSA内存访问成本,同时提升了FFN层的通道通信效率。
计算效率优化
⾃注意⼒头的冗余问题
多头⾃注意⼒机制(MHSA)是Transformer模型的核⼼模块,通过在多个⼦空间内计算不同的注意⼒
图,来捕捉不同的特征。然⽽,研究表明,很多注意⼒头学习到的注意⼒图是相似的,导致了计算冗余。
分组级联注意⼒ (Cascaded Group Attention)
为了解决注意⼒头的冗余问题,EfficientViT提出了⼀种新的注意⼒模块,称为分组级联注意⼒(Cascaded Group Attention, CGA)。其核⼼思想是:
• 分组输⼊:与传统的MHSA对所有头使⽤相同的特征输⼊不同,CGA为每个注意⼒头分配不同的特
征⼦集,从⽽减少计算冗余。
• 级联设计:在每个头计算完注意⼒图后,其输出会作为下⼀个头的输⼊,这样通过逐步细化的⽅式,进⼀步提升特征表⽰的丰富度。
CGA 的计算公式为:
\[
\hat{X}_{ij} = \text{Attn} \left( X_{ij} W_i^Q, X_{ij} W_i^K, X_{ij} W_i^V \right)
\]
\[
\hat{X}_{i+1} = \text{Concat} \left( \left[ \hat{X}_{ij} \right]_{j=1}^h \right) W_i^P
\]
通过这种设计,EfficientViT不仅减少了计算冗余,还提升了模型的深度和表⽰能⼒。CGA的两⼤优势体现在:
1. 通过分组减少冗余:使⽤不同的特征⼦集进⾏注意⼒计算,可以有效提升每个头的多样性。
2. 通过级联提升深度:在不增加额外参数的前提下,级联设计增加了⽹络的深度,进⼀步增强了模型的表达能⼒。
参数效率优化
参数冗余问题
传统Transformer模型在参数配置上通常遵循⾃然语⾔处理(NLP)中的设计策略,例如Q、K、V投影
层的宽度相同,FFN中的扩展⽐设置为4。然⽽,对于轻量级的视觉Transformer模型,直接沿⽤这些设计会导致参数冗余,尤其是在较浅层的⽹络中。
Taylor剪枝和参数重新分配
为了提⾼参数效率,EfficientViT采⽤了Taylor结构剪枝⽅法。通过分析每个通道的重要性,EfficientViT⾃动找到了⽹络中最重要的部分,并重新分配了参数。具体优化策略包括:
• 缩⼩Q、K投影层的维度:在⾃注意⼒模块中,Q和K的维度冗余较⼤,因此将其维度设置得较⼩。
• 保留V投影层的维度:V投影层对模型的表⽰能⼒影响较⼤,因此保留其较⼤的维度。
• FFN扩展⽐例的调整:将FFN的扩展⽐从传统的4调低⾄2,以减少不必要的参数。
剪枝后的模型在保持较⾼准确率的同时,显著减少了不必要的参数,提升了推理速度。
三、EfficientViT构建
EfficientViT的整体架构由三个主要部分组成:嵌⼊层、多级EfficientViT块和分类块。
EfficientVit 结构图
嵌⼊层
EfficientViT使⽤重叠Patch嵌⼊层将输⼊图像分割为16×16的Patch,并将其嵌⼊到⼀个特征空间
中。这种重叠设计能够增强低层视觉特征的学习能⼒,从⽽提⾼模型的整体表现。
多级EfficientViT块
整个⽹络结构由三个级联的EfficientViT块组成,每个块之间通过下采样层进⾏连接。下采样层通过⼀
个倒残差模块来实现,在降低分辨率的同时尽可能减少信息损失。每个EfficientViT块内部则由多个
Sandwich布局的EfficientViT单元堆叠⽽成。
每个块的设计可以概括为:
1. 第⼀阶段:处理分辨率最⾼的特征,特征通道数较⼩,但计算量⼤。
2. 第⼆阶段:对特征进⾏降维,增加通道数,减少特征图的分辨率。
3. 第三阶段:进⼀步降低分辨率,增加特征图的深层表⽰能⼒。
分类模块
在所有EfficientViT块处理完后,特征图会通过全局平均池化层进⾏汇总,最终通过全连接层进⾏分
类。为了提⾼推理速度,EfficientViT使⽤了BatchNorm归⼀化层和ReLU激活函数,⽽不是传统的LayerNorm和GELU,这些选择在⼀定程度上减少了推理时间。
四、EfficientNet改进EEG SOTA的方案
1. FBCSP 与 深度学习模型的融合
FBCSP(Filter Bank Common Spatial Pattern)是⼀种经典的脑电信号特征提取⽅法,通常⽤于提取
频率特征。将 FBCSP 与深度学习模型相结合,可以增强模型对频率域和时空特征的联合理解。
具体实现思路:
• FBCSP 特征提取:⾸先,使⽤ FBCSP 从原始 EEG 数据中提取频率域特征。FBCSP 在不同滤波器下
提取的特征可以直接作为新模型的输⼊。
• CNN 或 EEGNet:然后将这些特征输⼊到 CNN 或 EEGNet 等深度学习模型中。CNN 和 EEGNet 具
有较强的时空特征提取能⼒,能够进⼀步提取时空模式。
• 融合策略:可以通过级联(concatenation)或并⾏(parallel)的⽅式,将 FBCSP 提取的频率特
征与深度学习模型提取的时空特征进⾏融合。最终通过全连接层或分类层进⾏决策。
优点:
• 频率与时空特征的结合:FBCSP 提取的频率特征与 CNN/EEGNet 提取的时空特征相结合,能够更
好地捕捉脑电信号中的关键信息。
• 多样化特征:通过 FBCSP 提取不同滤波器下的特征,可以丰富特征空间,并提⾼模型的泛化能
⼒。
2. SNN 与 EEGNet 或 EfficientViT 的融合
SNN(Spiking Neural Networks,脉冲神经⽹络)能够更好地模拟⼤脑的神经活动,处理时间序列数
据具有天然优势。结合 SNN 与 EEGNet 或 EfficientViT 可以进⼀步提升对时序数据的处理能⼒。
具体实现思路:
• SNN 前置模块:在输⼊层使⽤ SNN 模块处理 EEG 数据的时间动态特征。SNN 可以有效捕捉 EEG
数据中的时间依赖性和突发性事件。
• EEGNet 或 EfficientViT 提取空间特征:将 SNN 提取的时序特征输⼊到 EEGNet 或 EfficientViT
中,进⼀步提取空间模式和语义特征。EEGNet 注重低计算复杂度下的空间特征提取,⽽EfficientViT 则通过 Vision Transformer 架构来建模全局依赖关系。
• 融合策略:可以通过两种⽅式实现融合:
a. 串联⽅式:将 SNN 提取的时序特征作为 EEGNet 或 EfficientViT 的输⼊。
b. 并联⽅式:SNN 与 EEGNet/EfficientViT 并⾏⼯作,分别提取时序和空间特征,最后通过特征融合层进⾏特征合并。
优点:
• ⽣物启发:SNN 模拟神经元活动,能够更好地处理时间序列数据,与 EEG 数据的时间依赖性⾼度契合。
• 全局与局部特征的结合:EfficientViT 提取的全局依赖特征与 SNN 提取的局部时间特征可以互
补,从⽽提升模型对复杂脑电图信号的理解能⼒。
3. EfficientViT 与 CNN 或 EEGNet 的融合
EfficientViT 是⼀种轻量级的 Vision Transformer 模型,在视觉任务上具有良好的表现。结合
EfficientViT 与 CNN 或 EEGNet 可以更好地提取 EEG 数据的全局和局部特征。
具体实现思路:
• EfficientViT 提取全局依赖特征:利⽤ EfficientViT 捕捉 EEG 数据的全局时空依赖性。
Transformer 能够建⽴⻓时间的依赖关系,适⽤于 EEG 数据中⻓时间段的模式提取。
• CNN 或 EEGNet 提取局部特征:CNN 或 EEGNet 可以关注 EEG 数据的局部时空特征,特别是
EEGNet 专⻔为 EEG 数据设计,能够有效提取空间结构信息。
• 多尺度特征融合:将 EfficientViT 提取的全局特征与 CNN 或 EEGNet 提取的局部特征进⾏多尺度融
合。可以通过注意⼒机制或多尺度特征融合层来实现不同尺度特征的柔性组合。
优点:
• 全局与局部特征的结合:EfficientViT 提供全局依赖建模能⼒,CNN 或 EEGNet 提供局部时空特征提取能⼒,两者结合可以提升对复杂数据的建模能⼒。
• 计算效率⾼:EfficientViT 和 EEGNet 都是轻量级模型,结合后可以在保持⾼效计算的同时提升模型性能。
4. 多模型集成
另⼀种创新⽅法是通过 集成学习(Ensemble Learning) 融合多个模型的预测结果。可以将 FBCSP、
SNN、EEGNet 和 EfficientViT 等模型的输出进⾏集成(平均或加权平均),从⽽提升最终模型的鲁棒性
和泛化能⼒。
具体实现思路:
• 多模型训练:分别训练 FBCSP+CNN、SNN+EEGNet、EfficientViT 等多个不同架构的模型。
• 集成策略:通过平均、加权平均或投票机制,对不同模型的预测结果进⾏融合。也可以通过元学习
器(Meta-Learner)对多个模型的输出进⾏学习,进⼀步提升集成效果。
优点:
• 鲁棒性更强:集成多个模型后,能够减⼩单个模型对某些特征的偏⻅,提升模型在不同数据集上的泛化能⼒。
• 性能提升:集成学习常常能够带来性能上的提升,特别是在 EEG 数据这种复杂多样的任务上。
5. 对⽐学习(Contrastive Learning)与⾃监督学习相结合
可以尝试将 对⽐学习 或 ⾃监督学习 ⽅法与上述模型相结合,特别是在数据量有限的情况下。通过⽆
监督或⾃监督的⽅式预训练模型,再进⾏微调,可以提升模型的特征提取能⼒。
具体实现思路:
• 对⽐学习:在预训练阶段,设计对⽐学习任务,学习 EEG 数据的时空特征。
• ⾃监督学习:通过预训练模型在未标记的 EEG 数据上学习时空特征,然后在分类任务上进⾏微调。
优点:
• 更好的表征学习:⾃监督学习能够捕捉 EEG 数据中的隐藏模式,提升模型在有限标注数据下的表现。
• ⾼效利⽤数据:特别适⽤于 EEG 这种标注数据稀缺的场景。
6. 哪种集成学习⽅法更适合模型处理EEG?
1. 多数投票(Majority Voting)
多个模型的预测输出中,选择最多模型预测的类别作为最终的预测结果。对于分类任务,这种⽅法简
单直接,尤其在个体模型效果差别不⼤的情况下,可以稳健地提升整体性能。
2. 加权平均(Weighted Average)
给每个模型的预测结果赋予不同的权重,然后将加权后的预测结果相加,再根据结果选择最终类别。
权重可以根据交叉验证的模型性能来设置。加权平均在模型性能差异较⼤时效果更好。
3. 最⼤概率(Max Probability)
从各个模型的输出中选择概率最⼤的那个类别作为最终的预测结果。这种⽅法类似于投票,但考虑了
模型预测强度。
4. 集成后的元学习(Meta-learning on Ensembles)
使⽤⼀个⾼层次的模型(如逻辑回归、XGBoost等)来学习如何组合多个模型的输出。这种⽅法复杂
度较⾼,但可以更好地利⽤各个模型的优点,尤其在数据复杂且噪声较多的情况下表现优异。
哪种⽅法在集成EEG数据时可能更有效?
对于EEG数据,以下因素需要考虑:
• 数据噪声与复杂性: EEG数据常常包含噪声和较⾼的复杂性。
• 模型的多样性: 不同模型的特征提取和分类⽅式各异。
基于这些因素,加权平均和集成后的元学习⽅法可能更适合,它们能够在⼀定程度上缓解噪声影响,
并充分利⽤各模型的优势。